来源:搜狐 时间:2023-10-18 11:35:03
方案非常简单,核心点在于如何获取每个节点最新的LSN呢?参照PolarDB[1]的解法,可以有两种方式:
(1)查询通道返回,即每次查询操作结果中返回LSN信息;
(2)节点定期上报最新的LSN点位;
当然也有其他方式获取比如建立长链接通道、消息中间件、服务发现机制等,考虑架构复杂性、性能损耗、实际收益等因素个人认为PolarDB的处理方式比较得当;LSN数据不需要落地,维护在session内存即可,链接断开后数据随之销毁。
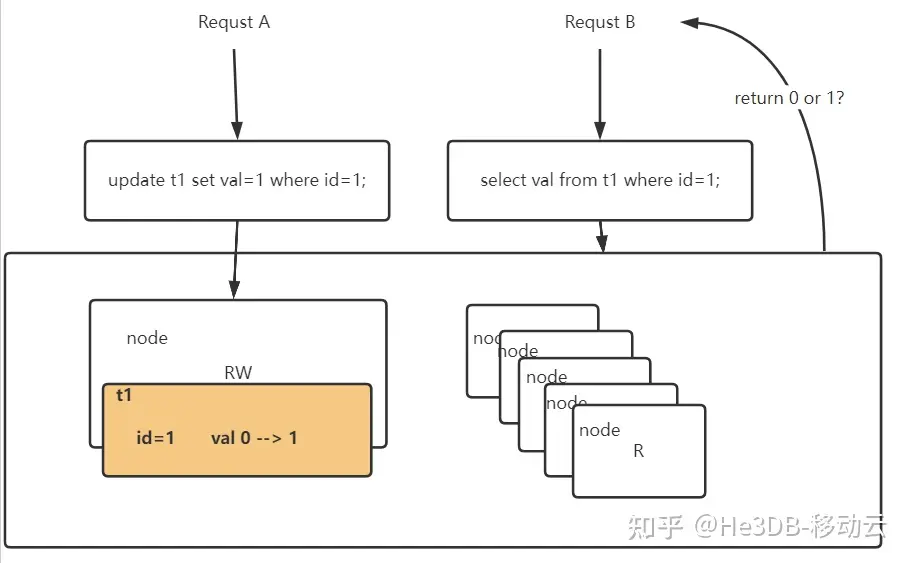
看到这里你可能会问并发大的情况下岂不是主库压力会非常大?
传统数据库中从机回放速度相对较慢,大并发下因从机未完成回放,请求只能落到主节点,确实会造成主节点压力过大,需要结合实际业务去权衡方案。
在云原生数据库He3DB架构下,得益于数据的物理复制,速度极快,可能在主节点数据返回时,数据复制已经开始,也就是说下次查询请求到来时,极可能读节点已经可以提供最新数据的查询,所以在这种架构体系下,主节点压力并不会太大,读节点可以分摊查询请求。
进一步细化,我们可以将LSN信息的维护细化到表粒度,这样可以提高负载的精确性,比如更新t2返回的LSN为88,紧接着查询的是t1数据,它的最大LSN才到77,因此可以选择LSN>=77的节点进行负载,而不是>=88。
He3Proxy中我们选择复用PG的系统表pg_stat_replication的数据维护LSN和节点的关系,连接建立时先查询pg_stat_replication中的数据,维护基础的node与LSN关系,并通过后续连接查询结果中携带的LSN信息更新关系。接着讨论下如何在返回结果中携带LSN信息呢?
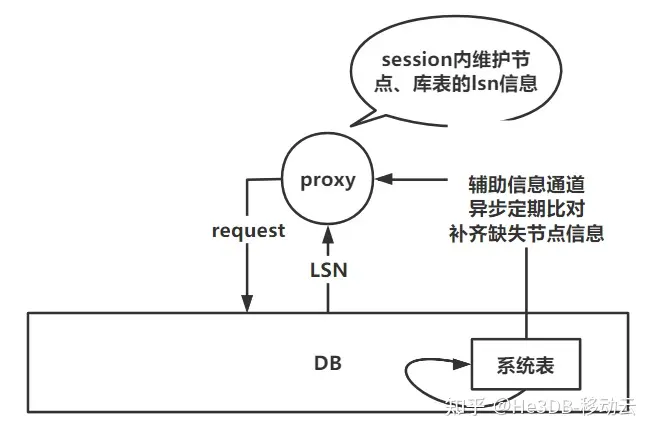
LSN维护方式
He3Proxy通过改造PG协议,新增LSN信息返回的新消息,需要计算层He3PG配合同步修改,因计算层消息协议的变动会影响客户端的连接使用,我们通过新增环境变量的方式区分连接He3PG的是He3Proxy还是其他客户端,只有He3Proxy连接时才返回LSN信息,避免用户使用其他客户端连接时引起报错,具体消息格式设计参考PG协议中的一般消息体格式,具体如下:
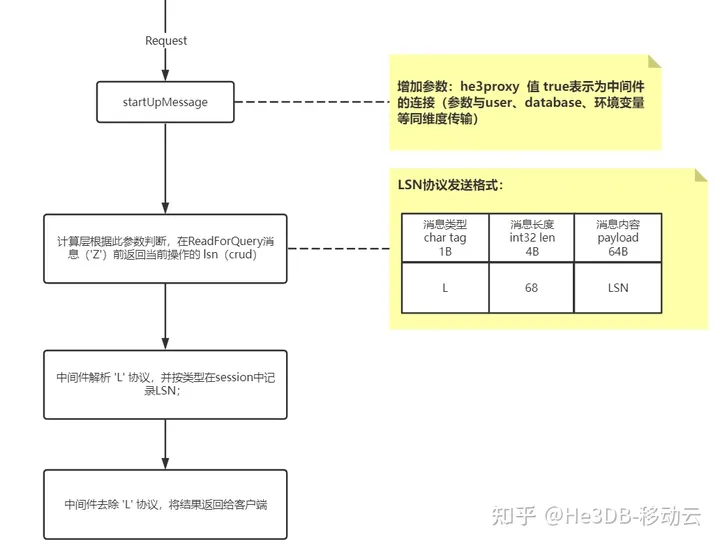
LSN返回的消息格式
通过以上方式He3Proxy即可在每次查询结果中取到最新LSN信息,并且每次查询结果集中只返回一次LSN,相比通过表扩展字段、隐藏列等方式维护更加简洁,同时通过startUpMessage阶段的变量信息控制是否返回LSN格式的消息,以兼容非He3Proxy的客户端连接。(个人认为因涉及计算层配合改造,这可能也是大多数开源中间件不做读一致性的原因吧)
这种方案强调了session内的一致性,为什么是session内?放到全局行不行?
我认为主要有以下几点原因:
(1)session内对事务的处理相对容易,能很好的处理可见性问题(事务中不同session数据可见性不同);
(2)session内保证请求有序,且LSN信息维护在session内存中;全局情况下,当高并发查询、更新数据时,维护LSN信息时可能需要锁机制,增加复杂性的同时也会影响性能。
某些场景对一致性要求极高,除了会话内部有逻辑上的因果依赖关系,会话之间也存在依赖关系,例如在使用连接池的场景下,同一个线程的请求有可能通过不同连接发送出去。对数据库来说这些请求属于不同会话,但是业务逻辑上这些请求有前后依赖关系,此时会话一致性便无法保证查询结果的一致性。
如何保证全局一致性呢?
1)请求全部由主节点执行
方案简单,逻辑简单,但也把集群能力限制在了单点,方案基本不可取,适用场景局限于写远大于读的场景;这里不做过多的讨论。
2)proxy等备节点完成回放后,再负载请求
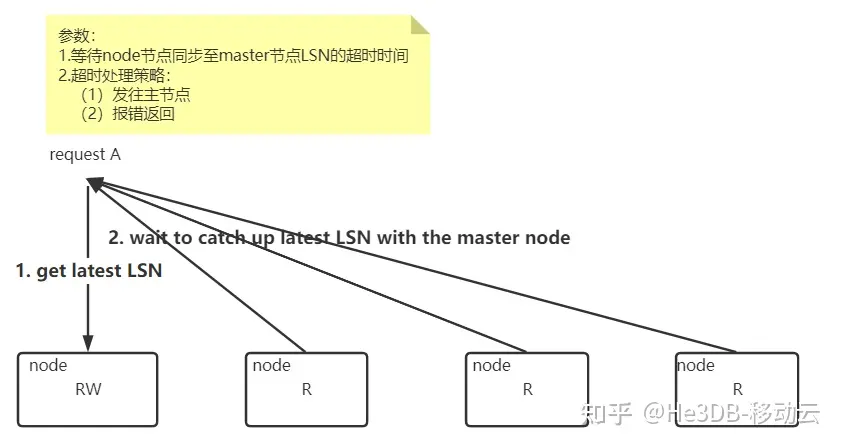
全局一致性
会话一致性的基础上,每次读请求都会到主去获取最新的LSN(系统表查询),然后等备节点回放达到主LSN时,进行负载均衡;因为全局一致性保障所有连接具有相同的读数据,因此He3Proxy连接通道内存中无需维护LSN信息,LSN维护粒度也无需到库表粒度,节点维度即可。并由两个参数控制保证执行效率:
发往主节点;<br>报错返回;
**方案优点:**减少主节点压力,适合读多写少场景;
**方案缺点:**需要等待主备同步,需要容忍一定的延时时间;
为进一步提升执行效率,HeProxy做了以下几点优化:
(1)减少从主获取最新LSN的次数,连续多个读请求时只查询一次pg_stat_replication;
(2)得益于He3DB存算分离、缓存分层设计(后续会有文章解析此部分设计,欢迎关注~),日志回放并不是所有节点都需要执行,并且内存buffer热数据节点与需要日志回放节点重合,因此日志回放速度得到较好保障,不会太慢;
(3)He3DB读节点内存分层设计决定了只读节点不对等,查询请求需要负载到对应有数据缓存的节点,因此He3Proxy不需要等待所有节点都完成回放,只要等待查询中涉及关键表的缓存节点完成回放即可;
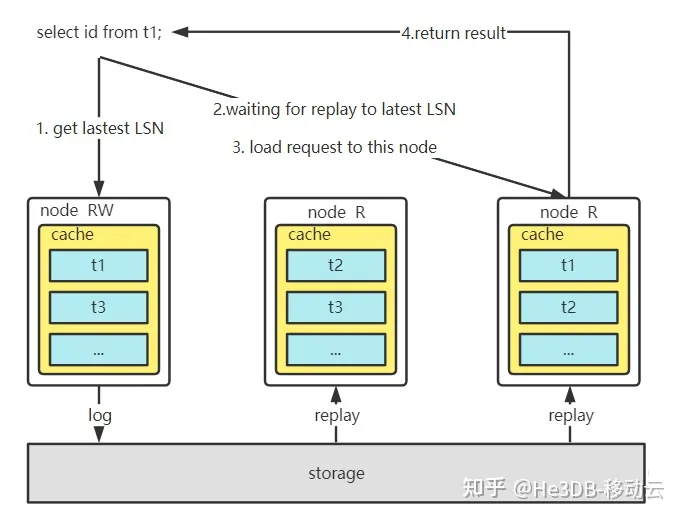
<br>读全局一致性执行流程
(4)业务系统中往往个别表需要保证强一致性,大多数表session一致性即可满足要求,因此He3Proxy进行了更细粒度的管理设计,支持按照库表粒度按需设置全局一致性,其余继续保持session一致性;
<1>He3Proxy解析执行操作涉及的库表;<br><2>元数据表维护哪些库表需要设置强一致性:<br>不指定表:所有库表都是session一致性;<br>指定表:指定表为强一致性,其他表维持session;<br>ALL:所有库表强一致性;<br><3>强一致性实现逻辑维持不变,涉及元数据中维护的库表同样先获取主最新LSN,待缓存节点的日志回放一致后进行负载均衡;
(5)后续He3DB也会考虑结合高性能硬件技术进一步降低日志同步、存储时间,降低主从数据同步时长。
总之性能和一致性是个矛盾,强一致性的保证势必造成性能的下降,我们能做的是为用户提供更多的选择方式,用户需要业务进行取舍。
相关推荐
猜你喜欢