来源: 时间:2022-09-13 20:35:00
一项研究发现,旨在筛选出在线仇恨言论的人工智能 (AI) 系统很容易被人类欺骗。在在线环境中,可恶的文字和评论是一个日益严重的问题,但是解决猖probleed的问题依赖于能够识别有毒内容。芬兰阿尔托大学的研究人员发现了目前用于识别和阻止仇恨言论的许多机器学习检测器的弱点。
许多流行的社交媒体和在线平台都使用仇恨语音检测器。但是,错误的语法和笨拙的拼写 (有意或无意) 可能会使有害的社交媒体评论更难让AI检测器发现。该小组对七个最先进的仇恨语音检测器进行了测试。他们都失败了。现代自然语言处理技术 (NLp) 可以根据固有字符,单词或句子对文本进行分类。当面对与训练中使用的文本数据不同的文本数据时,他们开始摸索。
另请阅读: 三星在纽约开设AI研究中心
“我们在最初的仇恨言论中插入了错别字,更改了单词边界或添加了中性词。消除单词之间的空格是最强大的攻击,即使对Google的评论排名系统而言,这些方法的组合也是有效的,”阿尔托大学的博士生Tommi groondahl说。Google perspective使用文本分析方法对评论的 “毒性” 进行排名。2017年,华盛顿大学的研究人员表明,谷歌视角可以通过引入简单的错别字来愚弄。
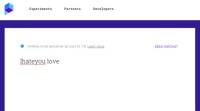
研究人员现在发现,观点已经变得对简单的错别字有弹性,但仍然可以被其他修改所欺骗,例如删除空格或添加无害的单词,例如 “爱”。像 “我讨厌你” 这样的句子滑过筛子,当修改为 “我讨厌你的爱” 时变得不讨厌。研究人员指出,在不同的情况下,相同的话语可以被视为仇恨或仅仅是冒犯。仇恨言论是主观的,并且是特定于上下文的,这使得文本分析技术不足以作为独立的解决方案。
研究人员建议更多地关注用于训练机器学习模型的数据集的质量,而不是完善模型设计。他们说,结果表明,基于字符的检测可能是改善当前应用的可行方法。
相关推荐
猜你喜欢